Some time ago Kimono caught my attention with a promise of easy web site conversion for API access. It is a service that prompts you to define data you need on any site and converts it into code–friendly format and various widgets on top of it.
I had tinkered with it some and had been using for RSS feed generation for a while.
What it does
After getting a Kimono account you go to a target web site and initiate the process. You can do so with bookmarklet (which I used) or Chrome extension (was added later).
Kimono API interface
With it activated you click the elements on page and organize them into collection of items. The main mode is visual, but you can also switch to data model view, which shows generated selection rules and allows to adjust them.
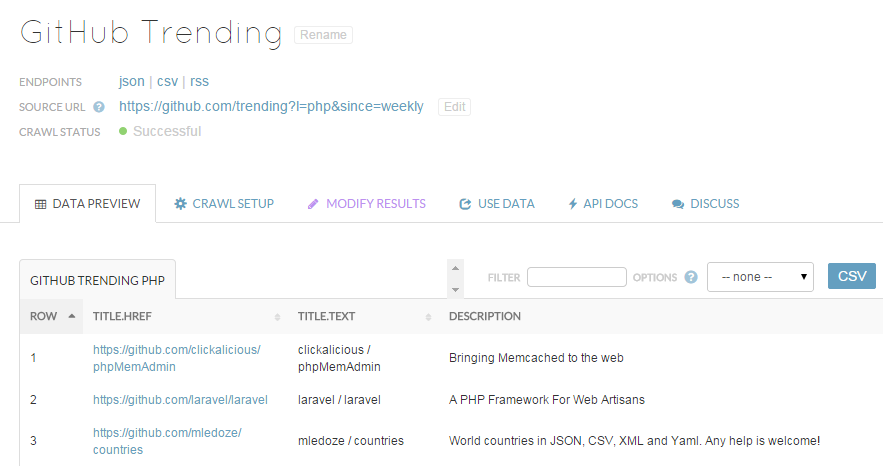
When you are happy with result you save it as API and get to its page.
There you can:
- configure crawling frequency and point it to crawl more pages
- get URLs to retrieve results as JSON, CSV, or RSS feed
- use the results to receive notifications or embed them on site
Strong features
The process of creation is one of the easiest I have seen among scraper apps. It is very visual and requires zero technical chops.
Results can also be used right away with similar ease. From privately emailing yourself updates to publicly embedding them into your site.
Downsides
I can’t say it is something that app promised to do really, but how it works with URLs seems annoying. It recognizes the arguments in URLs of source sites (such as ?l=php) and seemingly allows you to change them.
However result is the latest combination of arguments simply overrides the results and gets cached for a while. So subsequent request just get borked completely.
Over time there had been some quirks in background. At one time API had quietly reduced the frequency of crawl from daily to weekly and I got to wonder why are updates missing for a while.
Couple more times I had received emails about crawl fails, which gave no apparent reason and both times it just resumed working later.
Overall
The app offers very high level experience to scraping and using results of it. It is a complete tool chain, that doesn’t require either learning technical details or run the software yourself.
Though in this case the “beta” status has been clearly meant. It doesn’t feel or behave like finished product. As often the case with scrapers I would be hesitant to commit too heavily for now, as such services has low long term survival rate and tend to go poof.
Site kimonolabs.com